骁龙8至尊版2曝光, 但最有看点的地方并不是跑分
虽然距离正式发布大概还有一个多月,但疑似骁龙8至尊版2(SM8850)的跑分成绩已经在GeekBench的服务器上出现。
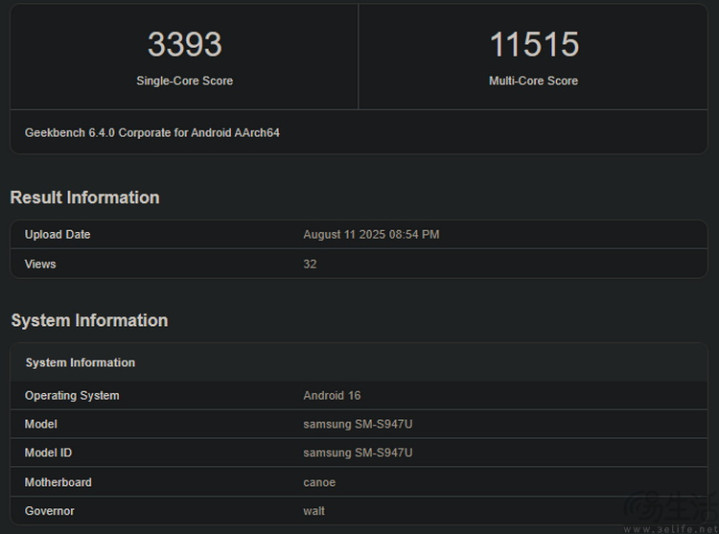
此次曝光的信息来自一台三星“SM-S947U”手机,所对应的可能是Galaxy S26 Edge。从跑分来看,它在GeekBench 6.4中获得了单核3393分、多核11515分的成绩。
如果大家有关注我们三易生活的评测内容,那么对于这样的成绩就可能不会感到太过惊奇。毕竟,这只比现款骁龙8至尊版的典型跑分水准(单核3000上下,多核10000上下),高出了大概10%而已。
那么这是否意味着,骁龙8至尊版2的CPU性能进步幅度不大呢?并不尽然。一方面,根据更进一步的信息来看,这台三星手机在整个跑分过程中,CPU的峰值频率只达到了4GHz,而不是“满血”的4.74GHz。这就表明它要么是遇到了过热节流问题,要么干脆就不是正式版的芯片或固件,所以频率就“没上去”,并不能代表骁龙8至尊版2的真实峰值性能。
但这次曝光的信息中真正让我们感到“触动”的,压根就不是骁龙8至尊版2的跑分数字本身,而是GeekBench除了性能测试之外,所“探测”的到其他东西。
从128位到2048位,骁龙新旗舰多了“超算血统”
我们先将视线集中在此次曝光的跑分截屏下方区域,在这里GeekBench列出了它所识别到的,骁龙8至尊版2所支持的一系列指令集信息。
从中可以清楚地看到,骁龙8至尊版2除了支持“古老的”neon指令集外,还支持sve和sme2这两个新得多的指令集。
这是什么概念呢?通过查询公开信息可知,neon指令集诞生于ARM v7时代,最早见于2005年的Cortex-A8架构,它最大支持128bit(位)的向量计算字长。
而sve和sme2则要“先进”得多,它们分别诞生于2016年和2021年,最初都是由超级计算机的CPU首发,用于AI训练等繁重的工作。所以这两个指令集最先进的地方,就在于它们都可以支持到最大2048bit的超大规模字长,甚至超过了目前x86服务器CPU所支持的512bit AVX指令。在它们被“移植”到移动平台后,这一关键技术特性也并没有被“阉割”。
当然,这并不是说高通给骁龙8至尊版2增加这两个新的指令集,就一定与超算有关(虽然他们确实可能有借助Oryon架构重回超算市场的打算)。
它们真正的意义在于,一方面sve和sme2作为ARM IP体系下最新的、旨在增强处理器浮点性能的指令集,相比于古老的neon,能够大幅增强现代ARM处理器在面对复杂多媒体任务的性能表现。说人话,就是能增强游戏、视频编辑等场景的CPU效率。而且这两个指令集在超算上本就是为AI而生,所以“移植”到移动端后,对增强CPU的AI计算能力自然就意义不小。
最新版的Intel指令集文档显示,AVX10.2将强制大小核全部支持512bit计算能力
另一方面,关注PC行业的朋友可能知道,目前消费级x86 CPU普遍支持256bit加速运算的AVX2指令集。最快到2026年,英特尔就会在NovaLake-S平台加入AVX10.2指令集,实现全部核心的512bit加速运算功能。
而现阶段的高通Oryon架构,因为只支持最大128bit的neon指令集,就导致其在PC平台(也就是骁龙X系列)上运行需要AVX2(256bit指令集)的程序时,效率大受影响。因此当骁龙8至尊版2加上最大能够实现2048bit向量计算的这两个新指令集后,就让我们会对大概率也将采用新架构的下一代骁龙X PC平台的性能、以及x86转译的兼容性,有了更高的期望。
下一代是变强了,可这一代反而成为了“奇迹”
如果大家以为,我们仅仅就只是因为骁龙8至尊版2引入了新指令集,可能会带来巨大的浮点性能改进而感到兴奋,就未免把事情想得太过简单了。
首先,大家都知道骁龙8至尊版是基于ARM v8.7 IP的架构设计,这意味着它在最底层的指令集上,要落后于苹果A18 Pro、联发科天玑9400、小米玄戒O1等竞争对手。因为后者全都是基于ARM v9.2的架构方案,从“根子上”来说,确实要比现在的骁龙8至尊版更先进。
苹果A18 Pro,ARM v9.2,有sve、也有sme2
联发科天玑9400,ARM v9.2 ,有sve、无sme2
小米玄戒O1,ARM v9.2,有sve、无sme2
那么这是否意味着,上述的这几款ARM V9.2的处理器,早就已经能支持sve、sme2这些先进指令集了呢?我们同样找来了它们的GeekBench跑分信息。可以看到,其中只有A18 Pro确实早早就内置了sve和sme2,而联发科和小米的ARM V9.2方案,就都只有sve,并未配备sme2指令集。
从ARM的商业模式来说,哪怕大家都是v9.2代次的架构,具体内置哪些指令集其实也是“可选”的。所以苹果敢于早早地实装先进的浮点加速指令集,很大程度上是因为他们有封闭生态,所以有信心可以“督促”开发者尽可能积极地对新架构、新指令集做适配。
而其他家的ARM v9.2方案不选择sme2,显然也不只是为了节约成本,而是多少有考虑到这一先进指令集在目前的安卓生态里还过于小众,即便硬件上了,也不一定能够促使开发者去主动进行适配。
但大家要知道,与它们同期的骁龙8至尊版,别说是没有sme2(因为它是与ARM v9绑定,基于v8.7的Oryon自然就不可能有),就连sve指令集也并没有配备。
换句话说,如果高通的竞争对手真能在2024年底到2025年秋季的这段时间,充分地宣传“使用ARM v9 CPU的好处”,并敦促那些游戏和大型APP开发者使用sve指令集,其实他们原本是有可能在性能上充分发挥出代次优势的。
可结果呢?大家都知道,无论是在本就支持sve、sme2的跑分软件里,还是在各主流游戏和生产力应用中,在上述这段时间里的那些、本来架构更先进的竞争对手,结果却并没有一个能够真正在“实际性能”上超越骁龙8至尊版。换句话说,也就是高通用了一个相对落后的底层设计,却做出了更好的实际表现。
要知道从以往的经验来看,这可不是一件容易的事情。比如早年间的英特尔Monahans(即PXA310)、英伟达Tegra2,甚至包括高通自己的双核版本Scorpion(MSM8260),都曾因为底层的指令集、架构缺憾,在市场宣发和“钱景”上遭遇了设计更完善竞争对手的“强烈冲击”。可到了骁龙8至尊版这里,却完全颠覆了“落后(架构)必然挨打”的常识,硬生生地用较老的底层设计,打翻了一票明明更先进的竞争对手。
优势不只取决于硬件,骁龙的表现再次证明了这一点
那么,骁龙8至尊版到底是怎么做到这种“反杀”的呢?
从硬件设计层面来说,大家都知道骁龙8至尊版与同期的竞品相比有两个明显特征,一是主频要高得多,二是去掉了L3和SLC缓存,用超大的、带宽更高的L2缓存取而代之。也就是说,高通当时的Oryon架构或许在底层指令集上“有点老”,但他们确实用了更高的成本,在硬件规模上堆出了当时“公版ARM架构”实现不了的超高主频和超大缓存。
相比之下,无论是同期的苹果和联发科,还是后来的小米,首先在处理器的部分单元设计上确实都呈现出逊色于高通的水准,至少它们都没能搞定那么恐怖的主频。
从部分平台明明用了ARM v9.2指令集,却“不愿意”实装sme2这个现象来看,所反映出的也不只是相关厂商想要节约成本这么简单。因为这实际上也体现出,它们对于说服开发者“抛弃”高通、专为自己做优化可能还缺乏信心。
其实这也很好理解。毕竟我们不久前在《高通攒了个“游戏生态”的局,再次秀出技术优势》中,报道过他们今年的“骁龙游戏技术赏”。在此次活动中,比起高通的代表,来自各大手机厂商、游戏引擎平台、游戏开发者方面的登台时间显然要长得多。从这些合作伙伴对于骁龙8至尊版硬件性能、开发工具,以及性能优化套件的盛赞来看,高通如今所取得的成绩,显然不仅仅是来自于硬件设计或者分优势那么简单。
而这也就很直接地提醒了目前所有的芯片厂商,比起单纯地追求硬件规格、架构方面的领先,生态和软件建设在很多时候也能对市场表现起到关键性的作用。当然,如果在这个基础上,硬件还能做到足够强大,那自然也就更加“无敌”了。
【本文部分图片来自网络】